Thesis Outline
posted by Hon Fai at 10:52 AM
0 comments
![]()
A diary of my MIT research activities. So I don't forget stuff that I have done and remember why i did them.

posted by Hon Fai at 1:22 PM
0 comments
![]()
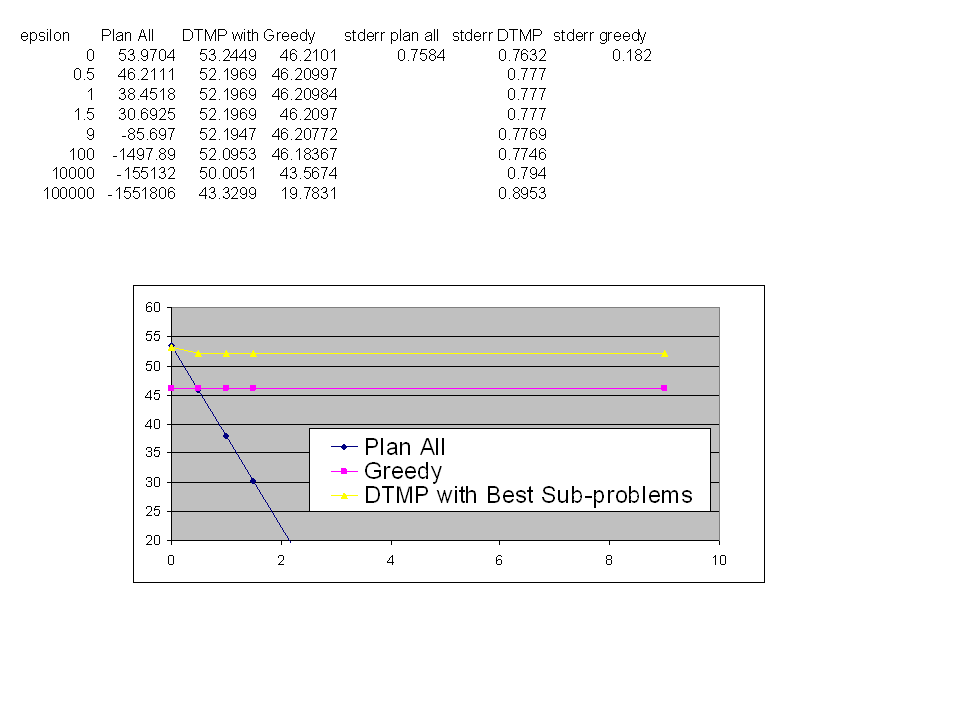
 The graph to the right is a preliminary result for the case of 2 vehicles and 4 targets located in a 2x2 region with fuel constraint of 4. The target were each valued at 10 each. note the legend is mislabelled. I have plotted on the graph the results of the DTMP, Plan all and a Greedy Strategy for varying values of epsilon. The Plan All policy assumes that all 2^4 or 16 subproblems were generated prior to solving the master level problem. The Greedy Algorithm consisted of alternating vehicles selecting the nearest target to add to its subset. The DTMP result does not perform as well as the plan all strategy for epsilon= 0. I believe that the decision tree which dictates the order of subproblem generation stop short in many cases resulting the what I referred to as the path completion problems in previous posts.
The graph to the right is a preliminary result for the case of 2 vehicles and 4 targets located in a 2x2 region with fuel constraint of 4. The target were each valued at 10 each. note the legend is mislabelled. I have plotted on the graph the results of the DTMP, Plan all and a Greedy Strategy for varying values of epsilon. The Plan All policy assumes that all 2^4 or 16 subproblems were generated prior to solving the master level problem. The Greedy Algorithm consisted of alternating vehicles selecting the nearest target to add to its subset. The DTMP result does not perform as well as the plan all strategy for epsilon= 0. I believe that the decision tree which dictates the order of subproblem generation stop short in many cases resulting the what I referred to as the path completion problems in previous posts.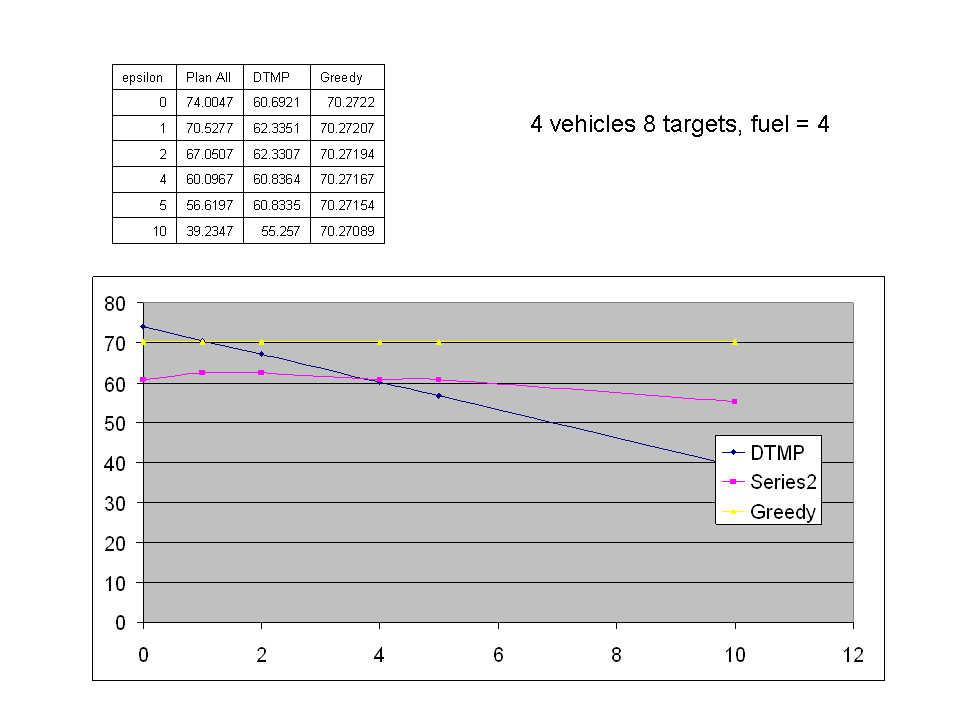 I am currently working to correct this problem.
I am currently working to correct this problem.
posted by Hon Fai at 3:28 PM
0 comments
![]()
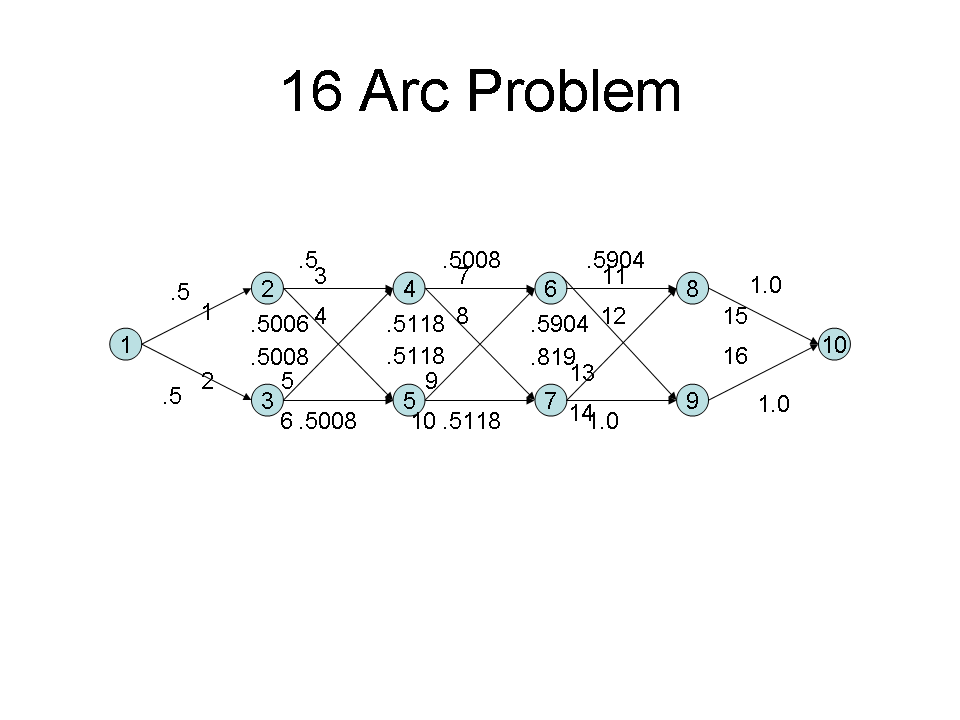 does not provide enough looks to find a complete path to the goal. Under these circumstances, I find the *optimal* path using the true arc costs of the known arcs, and the worst-case cost of the unknown arcs.
does not provide enough looks to find a complete path to the goal. Under these circumstances, I find the *optimal* path using the true arc costs of the known arcs, and the worst-case cost of the unknown arcs.
posted by Hon Fai at 9:16 AM
0 comments
![]()

posted by Hon Fai at 11:31 AM
0 comments
![]()
posted by Hon Fai at 12:51 PM
0 comments
![]()


posted by Hon Fai at 12:29 PM
0 comments
![]()

{kind=link}
{kind=link}