-State aliasing is defined in POMDPs as the phenomenon where several states of the system are aliased to the same observation. It is also referred to as the hidden state problem.
-State aliasing appears in the QL MDP model since several state configurations can map to the same QL. The MDP cannot distinguish between individual underlying states that map to the same QL.
-This creates a problem when it comes time to generate the transition and reward function for the MDP since transitions out of what would normally be distinct states in the Exact model are not blended together.
-One phenomenon that I have observed that confirms this suspicion is the following. I set the costs for all movement actions to be infinite, except when all arcs have been planned. Then I set the cost of movement to be the cost of moving according to the current plan. I also set the cost of planning to be zero. This encourages the MDP to plan all arcs and then to move. Under these circumstances, it makes no difference the order in which that arcs are planned.
-As expected, the policy does perform complete planning before moving. What is peculiar is that
the order in which the arcs are planned depends on the graph. Different graph instances result in different arc planning orders. The code is implemented such that it tries computing arcs in order from 1 to 12.
It will only swap the order when the value of planning a subsequent arc is strictly greater than the incumbent best arc. So it is expected that since it should make no difference which arc is planned first, the arcs should be planned in order. This behaviour is seen in the Exact MDP model, but
not here in the QL model.
-I believe now that the code is implemented correctly. The only reasons I can think of to explain this behavior is that the uniform sampling of the underlying graph worlds is biased in the QL MDP state space toward certain states. So a QL state, which contains multiple underlying states might have some good states blended in with some bad states, reducing the value of the QL state.
Addition of Rewards-When the rewards are reset to their average values, additional strange behavior occurs. Rather than planning arc 1-12 and then moving, the MDP sometimes decides to plan some, move, plan and move. In most instances this behavior still results in an optimal meta plan. Out of 1000 trial there are about 6-24 instances where this behavior results in reduced plan value.
-Again this is probably due the state aliasing.
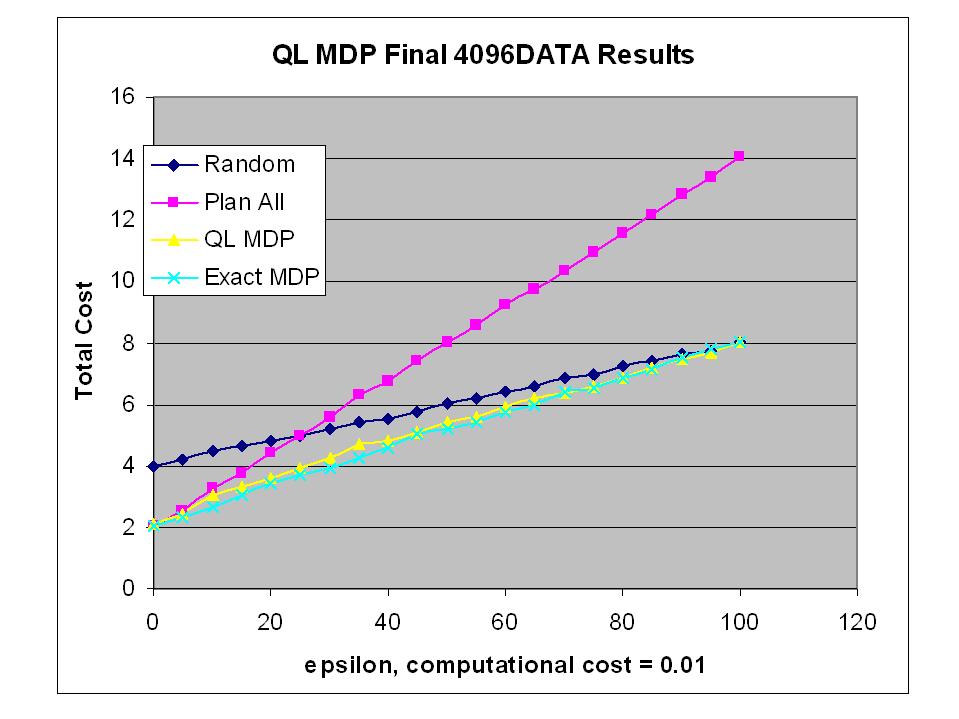
-The next thing that I will do is to generate results for the QL MDP for various epsilons.