Sampling and Tree Generation
The amount of sampling used in generating the initial tree has a huge impact on the resulting tree an in turn on the resulting metaplanning policy. Here are 3 trees based on 250,1000,4000, and 16000 samples.
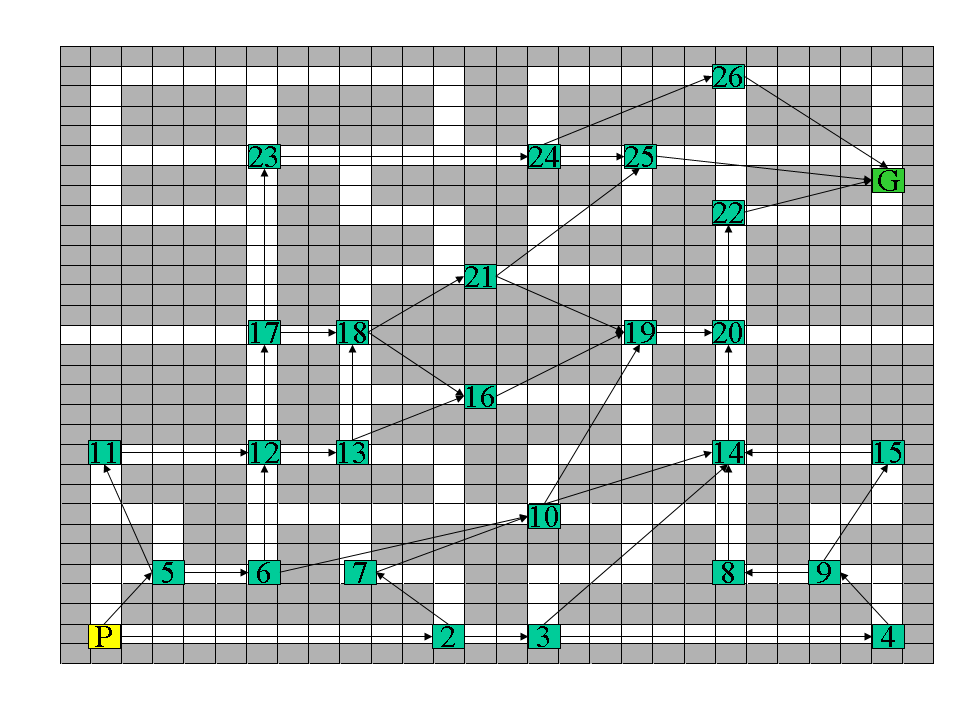
One thing to note which I discussed briefly in the previous post is that the decision tree predicts what the optimal solution will be given a set of arc outcomes. The key word being "optimal". That is if you knew the remaining arcs and were able to solve for the optimal path, on average it would take on the predicted cost. I believe that this is why the decision tree decides to generate leaf nodes, since all "optimal paths" have the same cost. It is still possible to find suboptimal paths, but the decision tree is not influence by this.
The story is differente when executing the metaplan, the optimal cost in not achievable because not all of the arc costs are known. The remaining arcs need to be selected carefully by the metaplanner, but as of yet there is no good way to do so.
The remainder of path was generated using a path completing algorithm that favored paths that had the most arcs computed. This would typically be that bad path because, the DTMP would follow queries deep in the tree, and discover a bad arc. Then the tree would run out of suggestions. So that the path closest to being completed would be the one with the bad arc.
One thing to note which I discussed briefly in the previous post is that the decision tree predicts what the optimal solution will be given a set of arc outcomes. The key word being "optimal". That is if you knew the remaining arcs and were able to solve for the optimal path, on average it would take on the predicted cost. I believe that this is why the decision tree decides to generate leaf nodes, since all "optimal paths" have the same cost. It is still possible to find suboptimal paths, but the decision tree is not influence by this.
The story is differente when executing the metaplan, the optimal cost in not achievable because not all of the arc costs are known. The remaining arcs need to be selected carefully by the metaplanner, but as of yet there is no good way to do so.
The remainder of path was generated using a path completing algorithm that favored paths that had the most arcs computed. This would typically be that bad path because, the DTMP would follow queries deep in the tree, and discover a bad arc. Then the tree would run out of suggestions. So that the path closest to being completed would be the one with the bad arc.
posted by Hon Fai at 12:51 PM
0 comments
![]()



{kind=link}